I'll admit it. I'm a document pack-rat. If it seems like a document might be useful to me at some point, even in the very distant future, I keep it. Several years ago, though, I realized that my filing system was a mess, and it was time to go digital. Even if every single document I had saved was incredibly useful, they'd never be useful if I couldn't find the right file at the right time. (Also, the papers were starting to pile up and turn my office into a huge mess.) My solution was to scan my paper files and organize them digitally. With the excellent OCR (optical character recognition) technology available in Adobe Acrobat Professional, I was even able to recognize the text in the scanned documents, enabling full-file searching in modern operating systems (e.g., Windows 7, OS X, most Linux distributions).
This feature of Acrobat Pro is especially useful for academics - how many times have you downloaded an older journal article and found the PDF contained images rather than text? Not very useful when you'd like to search for key words rather than read through every potentially relevant article...
Here's how to use Adobe Acrobat Pro to turn those image-based PDF files into searchable text PDF files: (Note: You must use Adobe Acrobat Professional for these tasks - Acrobat Reader doesn't have OCR capabilities, nor can it make changes to PDF files. Most well-equipped university computer labs will have Adobe Acrobat Professional available. If not, university students and faculty qualify for steeply discounted educational software prices direct from Adobe or your university bookstore.)
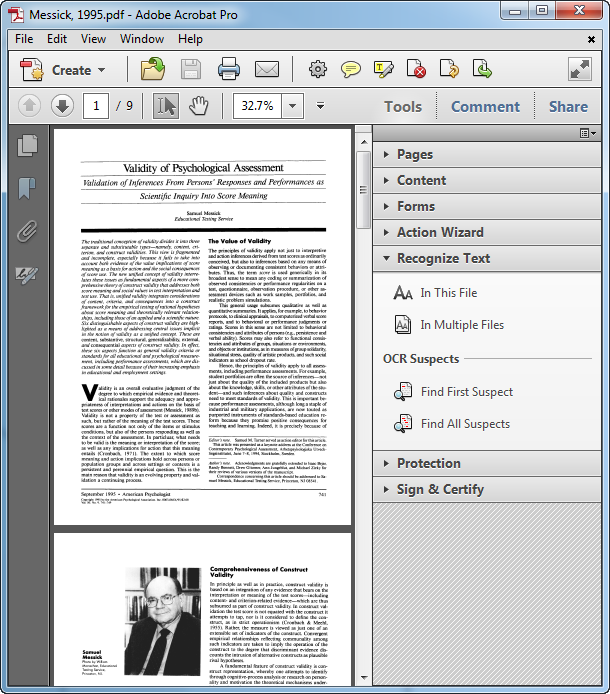
In the example below, I'm using a journal article I downloaded from American Psychologist. When I click in the document to try and select text (a good test for whether the document is already searchable), the entire page is selected in light blue as an image. This indicates that the PDF file is simply a set of page images, which means it isn't searchable.

To use Acrobat's OCR feature, click on the Tools pane, then select Recognize Text.* If you just want to recognize text in the open PDF file, choose In This File. If you've collected a bunch of PDF documents and wish to recognize them all in a batch operation, choose In Multiple Files.
For a single file, you'll see the following options appear:

If you're using Adobe Acrobat 8 or earlier, select OK, and Acrobat will begin recognizing the text on each page. Adobe Acrobat versions 9 and above contain an alternative PDF output style called ClearScan. This option replaces the text in the file with a custom Adobe vector font, which produces much clearer text and significantly smaller file sizes. This option does the best job of enhancing scanned document quality while producing reasonably sized PDF files for emailing or posting to course websites. To select ClearScan, click on the Edit button, then change the PDF Output Type: to ClearScan. Click on OK and OK again to begin the recognition.
Although ClearScan does take a bit longer to process, the results are outstanding, as you can see in the following images. The differences are even more dramatic with poorer quality initial scans.
Without ClearScan

With ClearScan

When the OCR process is complete, you'll notice that the document text is now selectable (and searchable).

Be sure to save the new (searchable) PDF file!
Additional Tip:
If you're using Adobe Acrobat in a computer lab, it's very likely that PDF files will open by default in Adobe Acrobat Reader. You may need to manually open Adobe Acrobat Pro and then open a PDF file in order to OCR documents.
*Note: In this example, I'm using Adobe Acrobat X Pro. If you have an older version of Adobe Acrobat, select the Document menu, OCR Text Recognition, Recognize Text Using OCR.